Tiempo de lectura: 4 minutos
El habla se considera la forma más natural de comunicación para los humanos.
Si anotamos todas y cada una de nuestras conversaciones a lo largo de un solo día, nos sorprendería saber cuántas suman. Estas pueden ser conversaciones privadas o públicas, con nuestros más cercanos y queridos, o no, según sea el caso, y con un acuerdo tácito en cuanto al grado de privacidad por parte de quienes participan en las conversaciones.
¿Con cuántas máquinas hablamos a diario?
La vida actual implica un grado cada vez mayor de interacción persona-máquina, y esta tendencia se ha multiplicado en los últimos años.
Cada vez utilizamos más nuestra voz para interactuar con nuestros dispositivos inteligentes: nuestro smartphone, nuestra televisión inteligente o nuestro altavoz inteligente.

Según el Informe de voz de Microsoft 2019 [1], 69% de los encuestados afirmaron que habían utilizado un asistente inteligente, y la mayoría (72%) interactuó a través de sus teléfonos.
A raíz de esta encuesta, se pronosticó que tres cuartas partes de los hogares estadounidenses tendrían al menos un altavoz inteligente para finales de 2020.
En cuanto a las cuestiones de privacidad, que abordamos anteriormente, en Europa, por ejemplo, el Reglamento General de Protección de Datos (GDPR) considera que una voz real es un dato personal, ya que además del mensaje que se transmite, también contiene información relacionada con el hablante (Información de identificación personal). – PII).
Aparte del mensaje hablado, ¿qué otros tipos de información pueden inferirse del habla? Se han llevado a cabo estudios sobre el análisis de la señal del habla en varios centros de investigación, incluido el Laboratorio de Investigación de Tecnología del Habla de Sigma, y han probado la viabilidad del modelado para predecir o estimar la identidad del hablante, junto con una variedad de características como la identidad del hablante. edad, género, estado de ánimo, acento e incluso altura, peso o trastornos que pueda padecer el hablante.
Hemos visto cómo Telefónica ha conseguido priorizar a las personas de 65 y más años en su atención al cliente durante el confinamiento, simplemente escuchando sus voces [2]. La Inteligencia Artificial ha hecho todo eso posible; es capaz de detectar las edades de los clientes desde el inicio de su llamada. Por otro lado, la biometría de voz en la banca ya está aquí. Se está consolidando como una solución del futuro, mediante la cual los usuarios podrán identificarse y realizar transacciones en su banco [3]. Así, la huella de voz se convierte en nuestra contraseña, provocando una mayor seguridad y una disminución de los casos de fraude.

Todas estas aplicaciones pueden almacenar nuestras muestras de voz o sus representaciones acústicas. Por ejemplo, cuando se utiliza la autenticación de voz, ya se han registrado ciertas muestras para que el sistema pueda reconocer la voz de un usuario y comprobar si se conoce su identidad. Pero va más allá: existen otros ámbitos como los call center, en los que normalmente las llamadas se graban y almacenan con diversos fines: cumplimiento de la ley, seguridad del cliente y de la empresa, análisis de la calidad del servicio o extracción de información agregada que pueda ser útil para las ventas, por nombrar sólo un ejemplo. Por último, cabe destacar que las grandes empresas involucradas con asistentes inteligentes también pueden acabar almacenando el habla de los usuarios, previo pedido de su consentimiento, para mejorar el rendimiento de los sistemas de reconocimiento de voz y de los sistemas de diálogo que forman parte de dichos asistentes.
Anonimización para combatir el uso fraudulento del discurso
La digitalización como proceso se ha visto impulsada por el estallido de la pandemia, lo que ha provocado un aumento sustancial de la ciberdelincuencia.. El FBI informó un 400% [4] Aumento de los ciberataques el año pasado. Esto, además del fraude que involucra técnicas de deepfake, que se utilizan desde 2019 [5] con el fin de simular la voz de alguien en particular, permitiendo así suplantarla al acceder a un sistema bancario, operar grandes cuentas o persuadir a otras personas a su alrededor. Es por eso que existe un riesgo real de ataques tanto a los sistemas que dependen de la interacción de voz como a las plataformas de almacenamiento de voz. Esto permitiría a los involucrados acceder a información confidencial contenida en una voz extrayendo las características inherentes de las personas y perfilando aunqueNosotros, la gente.
Es aquí donde vemos una necesidad crítica de desarrollar e implementar técnicas para garantizar la privacidad de la voz con el fin de brindar una protección sólida y segura contra la suplantación de voz.
podemos enumerar dos tecnologías generales a este respecto: criptografía y anonimización.
El primero implica la transformación de datos de voz en una representación sólo accesible a través de una clave privada y, en términos generales, implica un alto grado de complejidad y potencia informática.
Este último es más simple y flexible y nos permite ocultar "Información de identificación personal" (PII) dentro de la señal real. Hace unos años, estas técnicas eran muy limitadas y consistían en disfrazar sonidos o implementar técnicas de Transformación de Voz. Con la llegada del Deep Learning, el panorama ha cambiado en lo que respecta a la anonimización.
A continuación se muestra un ejemplo de esto, desglosado en una serie de etapas:
- Modelado del habla o transformación de la señal de audio en la representación acústica de un hablante.
- Eliminación de información personal que cause perturbaciones en las representaciones acústicas de los hablantes, al ocultar irreversiblemente información sensible sin alterar ninguno de los contenidos hablados.
- Síntesis de voz, orientada a tomar representaciones acústicas sin información sensible del hablante y convertirlas nuevamente en una señal de voz, aunque anónima.
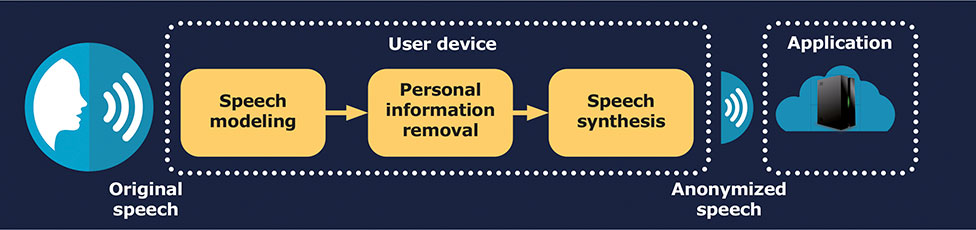
Sigma cuenta con la certificación ISO27001 al respecto y cumple en todos sus procesos con el RGPD 100%. La seguridad y la privacidad son primordiales en la etapa de recopilación y anotación de datos, así como en los sectores en los que Sigma participa (por ejemplo, call center, asistentes inteligentes, biometría, etc.). Es por eso que Sigma aplica técnicas de vanguardia en sus tecnologías de voz, ocultando así información sensible sobre las características del hablante dentro de la señal de voz, dependiendo del caso de estudio.
Esto puede ejemplificarse con el método de anonimización presentado como parte del Desafío VoicePrivacy 2020 [6] en el que fue uno de los contendientes más fuertes en términos de privacidad, manteniendo al mismo tiempo la inteligibilidad en el discurso anónimo recién creado.
La privacidad de los datos y el inexorable avance de la tecnología serán aliados en los próximos años. La innovación y la transformación digital parecen convertirse en un paradigma en el que la seguridad y protección del usuario son de suma importancia. ¿Estamos preparados para ello?
JUAN MANUEL PERERO & FERNANDO ESPINOZA
19 de julio de 2021
Laboratorio de investigación de tecnología del habla.
Inteligencia artificial Sigma
[/et_pb_text][/et_pb_column][/et_pb_row][/et_pb_section]