Reading Time: 4 Minutes
Speech is regarded as the most natural way for humans to communicate.
Were we to note down each and every one of our conversations over the course of a single day, we would be taken aback at how many they add up to. These may be private or public conversations, with our nearest and dearest, or not as may be the case, and with an unspoken agreement as to the degree of privacy on the part of those engaged in conversations.
How many machines do we talk to on a daily basis though?
Life today entails an ever-increasing degree of person-machine interaction, and this tendency has increased severalfold in recent years.
We are using our voices more and more to interact with our smart devices: our smartphone, our smart TV or our smart speaker.

According to Microsoft’s 2019 Voice Report [1], 69% of respondents stated that they had used an intelligent assistant, with the majority (72%) interacting via their phones.
Following on from this survey, it was forecast that three quarters of US households would have at least one smart speaker by the end of 2020.
As regards privacy concerns, which we broached earlier, in Europe for instance the General Data Protection Regulation (GDPR) considers an actual voice to be personal data, since besides the message being conveyed, it also contains information relating to the speaker (Personal Identifiable Information – PII).
Aside from the spoken message, what other kinds of information may be inferred from speech? Studies have been carried out on analyzing the speech signal in a number of research centers, including Sigma’s Speech Technology Research Lab., and these have tested the feasibility of modeling to predict or estimate speaker identity, along with a range of features such as the speaker’s age, gender, mood, accent, and even height, weight or disorders that the speaker might suffer from.
We have seen how Telefónica has managed to prioritize persons aged 65 and over in its customer care during lockdown, simply by listening to their voices [2]. Artificial Intelligence has made all of that possible; it is able to detect customers’ ages right from the beginning of their call. On the other hand, voice biometrics in banking are already here. It is establishing itself as a solution of the future, whereby users are able to identify themselves and make transactions at their bank [3]. Thus, the voiceprint becomes our password, bringing about increased security and a decrease in fraud cases.

All these applications may store our speech samples or their acoustic representations. For instance, when using voice authentication, certain samples have already been logged so that the system is able to recognize a user’s voice and check whether their identity is known. However, it goes beyond this: there are other arenas such as call centers, in which calls are normally recorded and stored for a variety of purposes: compliance with the law, customer and company security, analyzing service quality or extraction of aggregate information which may be useful for sales, to name but one example. Lastly, it is worth highlighting that large companies involved with intelligent assistants may also end up storing users’ speech, after first seeking their consent, in order to improve the performance of speech recognition systems and the dialog systems that constitute part of said assistants.
Anonymization in order to combat fraudulent speech use
Digitalization as a process has been boosted by the breakout of the pandemic, thereby leading to a substantial rise in cybercrime. The FBI reported a 400% [4] rise in cyber-attacks last year. This, in addition to fraud involving deepfake techniques, which have been in use since 2019 [5] in order to simulate the voice of someone in particular, thereby making it possible to impersonate them when accessing a banking system, operating large accounts, or persuading other persons around them. Which is why there is a real risk of attacks both on systems that rely on speech interaction, and on speech storage platforms. This would allow those involved to access sensitive information contained in a voice by extracting people’s inherent features and by profiling those people.
It is here that we see a critical need for the development and implementation of techniques for ensuring voice privacy in order to provide secure and sound protection against voice spoofing.
We can list two general technologies in this respect: cryptography and anonymization.
The former entails the transformation of speech data into a representation only accessible via a private key, and in general terms it involves a high degree of complexity and computing power.
The latter is simpler and more flexible, and lets us conceal “Personal Identifiable Information” (PII) within the actual signal. A few years ago, these techniques were very limited and entailed disguising sounds or implementing Voice Transformation techniques. With the advent of Deep Learning, the panorama has changed when it comes to anonymization.
There follows an example of this, broken down into a number of phases:
- Speech modeling or transformation of the audio signal into a speaker’s acoustic representation.
- Removal of personal information causing a disturbance to speakers’ acoustic representations, by irreversibly concealing sensitive information without altering any of the spoken content.
- Speech synthesis, geared toward taking acoustic representations minus sensitive speaker information, and converting them back to a speech signal, albeit anonymized.
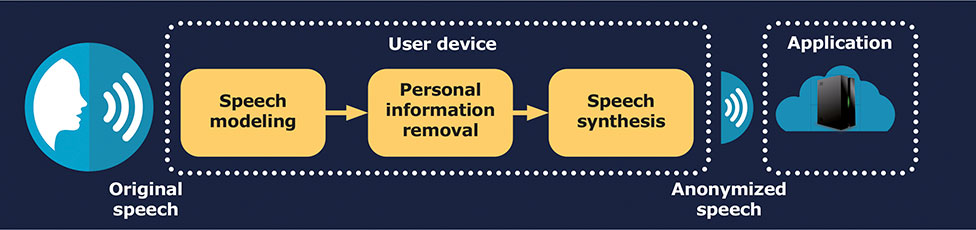
Sigma is ISO27001 certified in this respect, and is 100% compliant in all its processes with GDPR. Security and privacy are paramount at the data compilation and annotation stage, as well as in the sectors in which Sigma is involved (for instance, call centers, intelligent assistants, biometrics, etc.). Which is why Sigma applies cutting-edge techniques in its speech technologies, thereby concealing sensitive information concerning a speaker’s features within the speech signal, depending on the case study.
This can be exemplified by the anonymization method presented as part of the VoicePrivacy 2020 Challenge [6] in which it was one of the strongest contenders in terms of privacy, while maintaining intelligibility in the newly created, anonymized speech.
Data privacy and the inexorable advance of technology are set to be bedfellows for years to come. Innovation and digital transformation look to become a paradigm in which user security and protection are of the utmost importance. Are we ready for it?
JUAN MANUEL PERERO & FERNANDO ESPINOZA
July 19, 2021
Speech Technology Research Lab.
Sigma Artificial Intelligence
[/et_pb_text][/et_pb_column][/et_pb_row][/et_pb_section]